To address the limitation of existing driving benchmarks (focused on structured scenes/simulators while ignoring long-tail events), we integrated heterogeneous datasets (Waymo-E2E, DADA2000, LaF, StHa, SOM, AADV) into a unified framework aligned with four cognitive competencies: Perception & Understanding, Causal CoT Reasoning, Planning & Decision-Making, and Instruction Following. For Perception & Understanding, three subtasks were designed: 1) Small long-tailed objects: True/False questions built from dataset segmentation labels, with diverse question templates to boost generalization; 2) Long-tailed accident prediction: True/False questions based on dataset abnormal labels and timestamps, using varied prompts; 3) Long-tailed accident relationship: Multiple-choice questions where distractors are filtered/selected (random 2/4 options), shuffled, and mapped to A/B/C/D labels, with questions asking to describe the current situation.
For Causal CoT Reasoning, we leveraged future image sequences and ground-truth ego trajectories to ensure reasoning aligns with physical outcomes, requiring the chain to cover scene context, key interactive agents, their potential intentions, and justifications for the final driving action. Advanced VLMs were prompted with future planning results to generate accurate CoT, which was further manually calibrated.
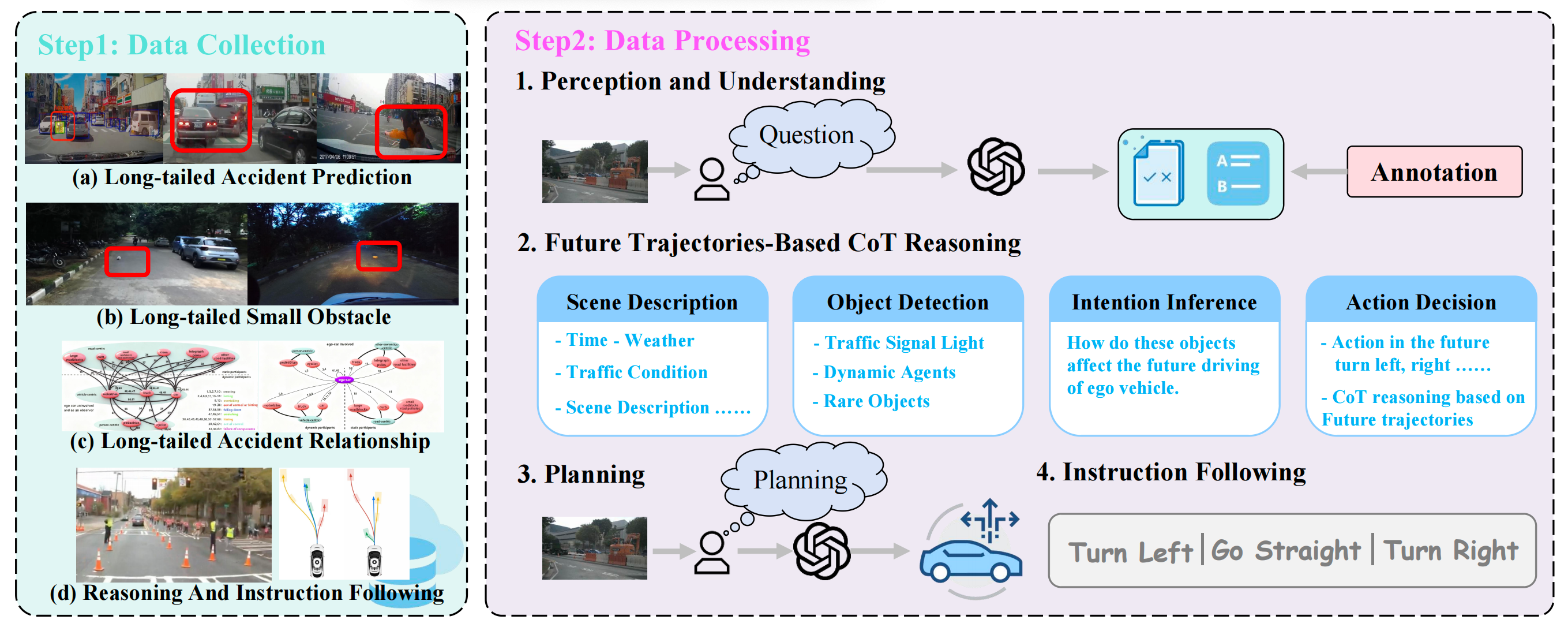
Dataset Construction Pipeline. This figure depicts the pipeline of data collection (integrating multiple challenging driving datasets) and data processing (featuring four task categories: understanding, chain-of-thought, planning, and instruction following) to train and assess the cognitive abilities of end-to-end autonomous driving models within a unified QA framework.